loaction
창의설계축전 공모작
강화학습 기반 차세대 저전력 6족 보행 로봇 제어
-
참가 부문
-
학과
전기·정보공학부
-
팀명
어스아워
-
신청자 이름
손현달
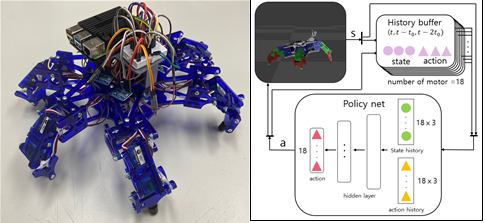
최근 로봇 분야에서, 보행 로봇은 험한 지형과 복잡한 환경에서 이동하기 유리하다는 점에서 바퀴나 캐터필러의 중요한 대체 이동 방식으로 주목받고 있다. 하지만 보행 로봇의 제어 모델 설계 문제는 복잡하여 시간과 전문성을 많이 요구한다. 따라서 본 과제에서는 기계학습의 한 분야인 강화학습의 알고리즘을 적용하여, 보다 쉽고 빠르게 보행 로봇의 제어 모델을 설계하고자 한다. 특히, 단순히 보행 속도만을 고려하는 것이 아니라, 전력 소모 대비 이동 효율이 좋은 모델을 목표로 한다. 여기서는 arcbotics 사의 6족 보행 로봇인 hexy를 대상으로 한다. URDF 파일을 시뮬레이터가 지원하는 파일형식으로 변환한 뒤에 로봇을 시뮬레이션 공간 상에 올린다. 소모전력 최적화, 안정적인 보행을 위한 reward function을 설계하고, 하이퍼파라미터를 적절히 튜닝한 Proximal Policy Optimization(PPO) 알고리즘을 사용해, 시뮬레이션에서 로봇을 학습시킨다. 최종적으로 학습된 모델을 실제 로봇에 연결된 라즈베리 파이에 업로드한다. 그림 1.에서 확인할 수 있는 바와 같이, 본 과제에서는 로봇의 제어에 적용되는 policy를 다층 퍼셉트론 확률 모델로 구현하였고, 그 학습 과정에 강화학습 알고리즘 중 하나인 PPO 알고리즘을 사용하였다. 모델의 학습 방향성을 결정하는 reward function 의 설계 과정에서는 ‘reward의 무차원화’라고 가칭한 기법을 적용해보았다. 이후 실제 로봇에 모델을 탑재할 때를 대비하여, 강화학습 모델이 상호작용하게 되는 환경을 최대한 현실과 가깝도록 토크, 속도 제한을 조절하였다. 이 모델은 기존의 다른 보행 모델에 비해 더 전력 효율적인 보행을 보였고, 이를 보편적으로 보행 로봇의 학습에 적용한다면 보행 로봇의 상용화에 대해 전력의 경제성을 보탤 수 있을 것이다.
담당부서학생행정실
전화번호880-2277