- About
- Academics
-
Undergraduate Programs
- Civil and Environmental Engineering
- Architecture and Architectural Engineering
- Mechanical Engineering
- Industrial Engineering
- Energy Resources Engineering
- Nuclear Engineering
- Materials Science and Engineering
- Electrical and Computer Engineering
- Naval Architecture and Ocean Engineering
- Computer Science and Engineering
- Aerospace Engineering
- Chemical and Biological Engineering
-
Graduate Programs
- Civil and Environmental Engineering
- Architecture and Architectural Engineering
- Mechanical Engineering
- Industrial Engineering
- Energy Systems Engineering
- Materials Science and Engineering
- Electrical and Computer Engineering
- Naval Architecture and Ocean Engineering
- Computer Science and Engineering
- Chemical and Biological Engineering
- Aerospace Engineering
- Interdisciplinary Program in Technology, Management, Economics and Policy
- Interdisciplinary Program in Urban Design
- Interdisciplinary Program in Bioengineering
- Interdisciplinary Program in Artificial Intelligence
- Interdisciplinary Program in Intelligent Space and Aerospace Systems
- Chemical Convergence for Energy and Environment Major
- Multiscale Mechanics Design Major
- Hybrid Materials Major
- Double Major Program
- Open Programs
-
Undergraduate Programs
- Research
- Campus Life
- Communication
- Prospective Students
- International Office
News
Computer Vision Research Lab at SNU College of Engineering Develops AI Video Generation Technology That Generates Endless Footage
-
Uploaded by
대외협력실
-
Upload Date
2024.11.11
-
Views
2,753
Computer Vision Research Lab at SNU College of Engineering Develops AI Video Generation Technology That Generates Endless Footage
- Overcomes existing models’ limitations of generating short clips, enhancing potential applications in film, advertising, and more
- Paper accepted for presentation at NeurIPS 2024, the most prestigious international conference in artificial intelligence
▲ (From left) Jihwan Kim, Researcher (Master's student, Interdisciplinary Program in Artificial Intelligence), Junoh Kang, Researcher (Ph.D. candidate, Department of Electrical and Computer Engineering), and Professor Bohyung Han (Department of Electrical and Computer Engineering, Interdisciplinary Program in Artificial Intelligence)
Seoul National University’s College of Engineering announced that the Computer Vision Lab (CVLAB), led by Professor Bohyung Han of the Department of Electrical and Computer Engineering, has developed “FIFO-Diffusion,” an innovative AI technology that generates infinitely long videos without requiring additional training.
FIFO-Diffusion addresses the inherent limitations of traditional video generation models, such as high memory consumption and frame inconsistency, particulary in long video generation. Recognized for its groundbreaking approach, the research paper, “FIFO-Diffusion: Generating Infinite Videos from Text without Training” has been accepted for presentation at NeurIPS 2024 (Neural Information Processing Systems), the leading international conference on artificial intelligence and machine learning. NeurIPS is renowned for showcasing cutting-edge advancements, with papers selected through an exceptionally rigorous review process.
Traditional video diffusion models face significant challenges when generating long videos, including quadratic memory requirements and a lack of frame continuity, often leading to unnatural visuals. To resolve theses issues, the CVLAB team introduced FIFO-Diffusion, which maintains constant memory usage while generating videos with smooth and consistent transitions between frames. By leveraging pretrained diffusion models for short clips, FIFO-Diffusion can produce high-quality, infinite-length videos conditioned on textual prompts without any additional training.
Especially three key innovations were implemented in this research to enhance video quality. First, the “diagonal denoising” technique processes frames at different noise levels in a queue, allowing for continuous video generation without quality degradation. Next, the “latent partitioning” approach reduces noise-level disparities between frames in a queue processing them in parallel by dividing the queue into several blocks. Lastly, “lookahead denoising” was introduced, where new frames reference earlier, more denoised frames, reducing visual loss in subsequent frames and enhancing video sharpness. Finally, the researchers demonstrated the feasibility of infinitely long video generation by applying these techniques in parallel on multiple GPUs to maximize efficiency, which further increased the speed and quality of video generation.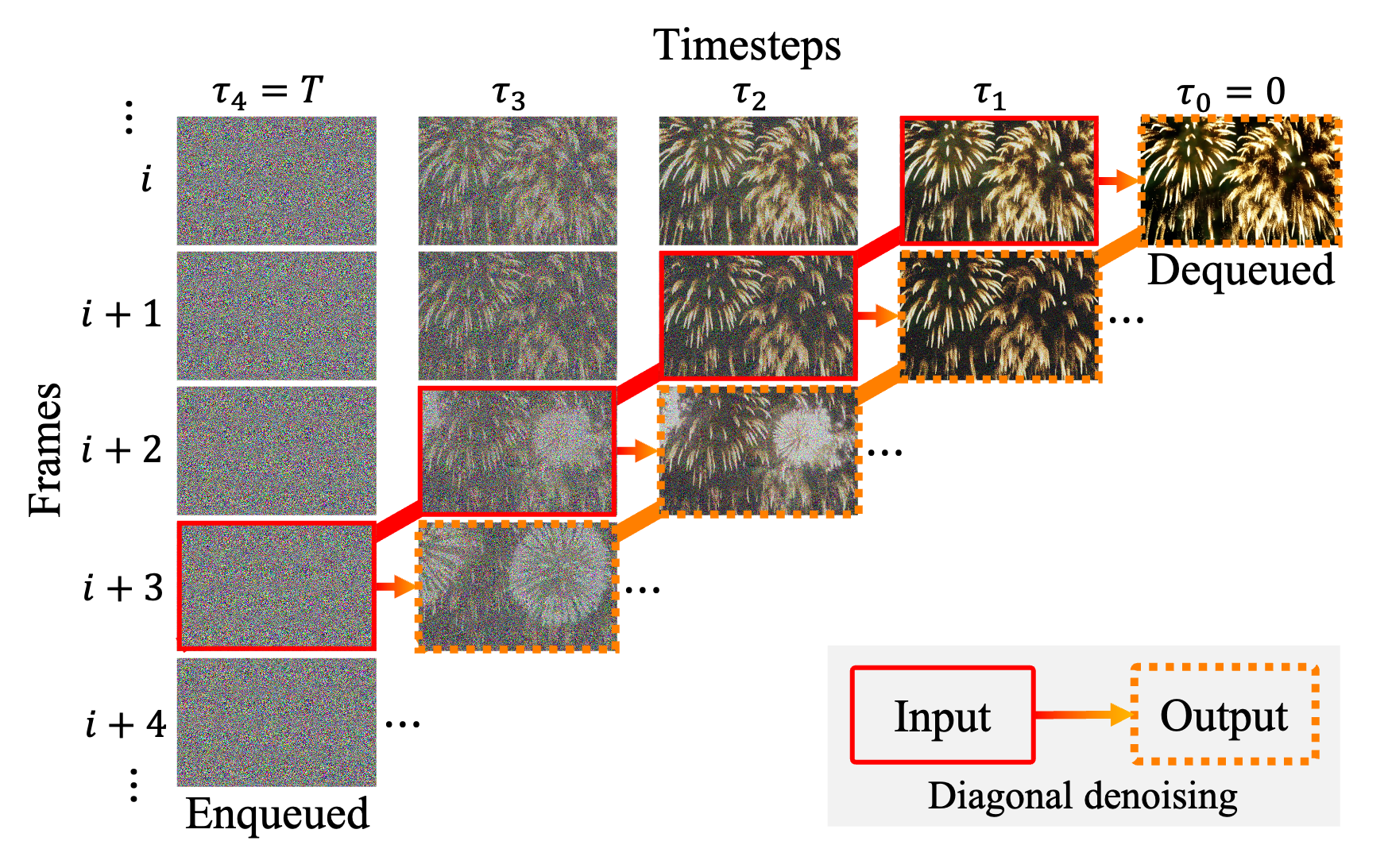
▲ Diagram of Diagonal Denoising: Different noise-level frames are input sequentially into the pre-trained diffusion model.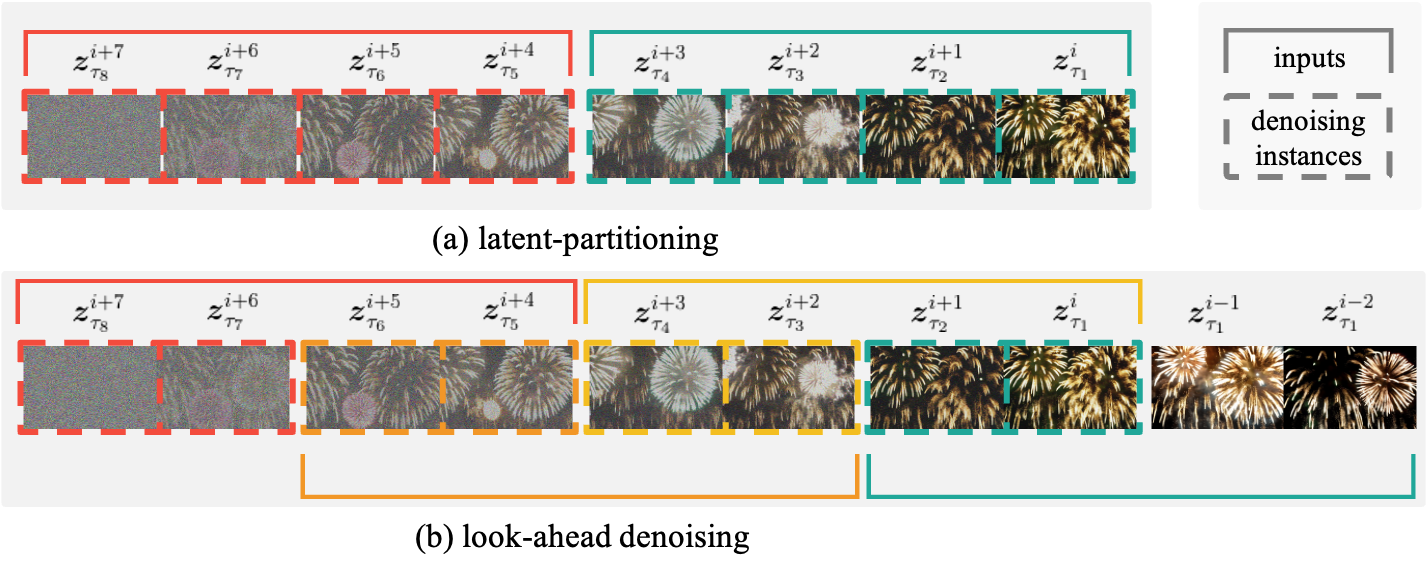
▲ Diagram of (a) Latent Partitioning and (b) Lookahead Denoising : Latent partitioning divides frames into blocks for parallel processing, while lookahead denoising references frames with less noise, generating sharper video outputs.
FIFO-Diffusion technology is expected to be widely utilized in a variety of content industries, including film, advertising, gaming, and education. While existing text-based video generation models can only generate short clips of three seconds or less, making it difficult to be used in real-world content production, FIFO-Diffusion technology overcomes this limitation, enabling more natural videos to be generated without any length restrictions. In addition, FIFO-Diffusion is expected to revitalize AI-based video content production because it does not require large hardware resources or massive data for training.
“FIFO-Diffusion, which breaks the limitations of existing video generation models, is significant in that it establishes a new concept of generating infinite-length videos without additional training,” said Professor Bohyung Han, who led the research. ”We plan to conduct various follow-up studies based on this technology in the future.” Lead author of the paper Jihwan Kim added, “This development lays the foundation for video generation technology to be widely used in the field of video content.”
Co-first authors Jihwan Kim and Junoh Kang, researchers in SNU’s Computer Vision Lab, are continuing in-depth research on video generation technologies.
[Reference Materials]
FIFO-Diffusion: Generating Infinite Videos from Text without Training, NeurIPS 2024
https://jjihwan.github.io/projects/FIFO-Diffusion
https://arxiv.org/pdf/2405.11473
[Contact Information]
Jihwan Kim, Researcher, SNU Computer Vision Lab / kjh26720@snu.ac.kr
Sanghyeok Chu, Researcher, SNU Computer Vision Lab / sanghyeok.chu@snu.ac.kr